Kube-scheduler
起承上启下的作用,首先负责接收controller manager创建新的pod,为其安排node,其次安排工作结束之后,目标node上的kubelet服务进程接管后续工作。
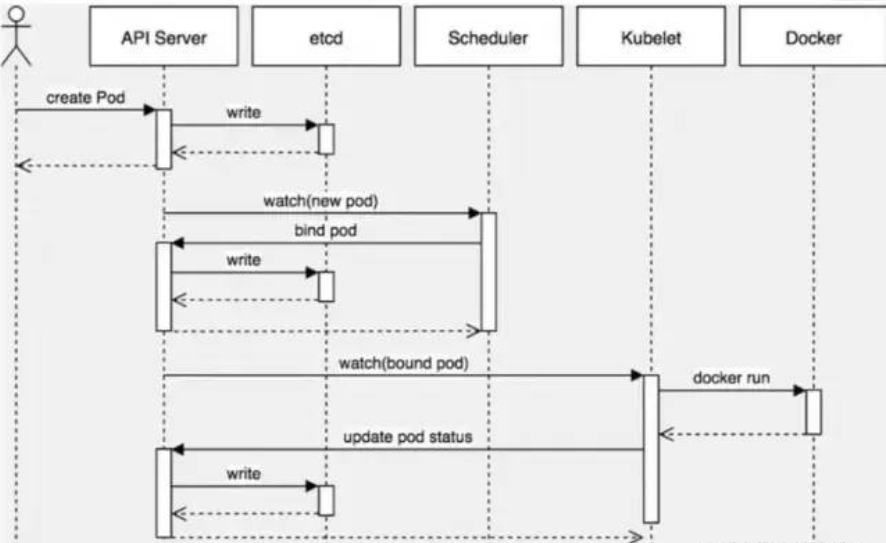
pod的创建
单独创建一个pod的流程
- 用户通过kubectl或者api客户端将创建的pod信息发送给apisever
- apiserver验证客户端的用户权限信息,验证通过开始处理创建请求生成pod对象信息,信息存入etcd,返回确认信息给客户端
- apiserver开始反馈etcd中pod对象的变化,其他组件使用watch机制跟踪apiserver的变动
- scheduler发现有新的pod对象要创建,调用内部算法机制为pod分配最佳的主机,将结果信息更新到apiserver
- node节点上的kubelet通过watch机制跟踪apiserver发现有pod调度到本节点,然后创建容器,结果反馈apiserver
- apiserver将收集到的pod信息存入etcd中
使用deployment创建pod
1、首先,用户使用kubectl create命令或者kubectl apply命令提交了要创建一个deployment资源请求;
2、api-server收到创建资源的请求后,会对客户端操作进行身份认证,在客户端的~/.kube文件夹下,已经设置好了相关的用户认证信息,这样api-server会知道我是哪个用户,并对此用户进行鉴权,当api-server确定客户端的请求合法后,就会接受本次操作,并把相关的信息保存到etcd中,然后返回确认信息给客户端。
3、apiserver开始反馈etcd中过程创建的对象的变化,其他组件使用watch机制跟踪apiserver上的变动。
4、controller-manager组件会监听api-server的信息,controller-manager是有多个类型的,比如Deployment Controller, 它的作用就是负责监听Deployment,此时Deployment Controller发现有新的deployment要创建,那么它就会去创建一个ReplicaSet,一个ReplicaSet的产生,又被另一个叫做ReplicaSet Controller监听到了,紧接着它就会去分析ReplicaSet的语义,它了解到是要依照ReplicaSet的template去创建Pod, 它一看这个Pod并不存在,那么就新建此Pod,当Pod刚被创建时,它的nodeName属性值为空,代表着此Pod未被调度。
5、调度器Scheduler组件开始介入工作,Scheduler也是通过watch机制跟踪apiserver上的变动,发现有未调度的Pod,则根据内部算法、节点资源情况,pod定义的亲和性反亲和性等等,调度器会综合的选出一批候选节点,在候选节点中选择一个最优的节点,然后将pod绑定该该节点,将信息反馈给api-server。
6、kubelet组件布署于Node之上,它也是通过watch机制跟踪apiserver上的变动,监听到有一个Pod应该要被调度到自身所在Node上来,kubelet首先判断本地是否在此Pod,如果不存在,则会进入创建Pod流程,创建Pod有分为几种情况,第一种是容器不需要挂载外部存储,则相当于直接docker run把容器启动,但不会直接挂载docker网络,而是通过CNI调用网络插件配置容器网络,如果需要挂载外部存储,则还要调用CSI来挂载存储。kubelet创建完pod,将信息反馈给api-server,api-servier将pod信息写入etcd。
7、Pod建立成功后,ReplicaSet Controller会对其持续进行关注,如果Pod因意外或被我们手动退出,ReplicaSet Controller会知道,并创建新的Pod,以保持replicas数量期望值
调度
主要包含两部分调度算法,predicates和priorities,predicates过滤部分不合格的node,priorities为所有node打分,选出最合适的
run方法启动
1.初始化scheduler 监听10251和10259端口,前一个不需要认证,后一个需要认证
2.启动事件广播
3.启动http server
4.启动所有的informer 这里只找非terminating的pod
5.选择leader
6.开始run循环,当informer的cache同步完成后执行选择某一个进行调度
sheduleOne()
从 scheduler 调度队列中取出一个 pod,如果该 pod 处于删除状态则跳过
执行调度逻辑 sched.schedule() 返回通过预算及优选算法过滤后选出的最佳 node
如果过滤算法没有选出合适的 node,则返回 core.FitError
若没有合适的 node 会判断是否启用了抢占策略,若启用了则执行抢占机制
判断是否需要 VolumeScheduling 特性
执行 reserve plugin
pod 对应的 spec.NodeName 写上 scheduler 最终选择的 node,更新 scheduler cache
请求 apiserver 异步处理最终的绑定操作,写入到 etcd
执行 permit plugin
执行 prebind plugin
执行 postbind plugin
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。