redis的基本类型
String
redis的字符串是字节序列,是二进制安全的,512M为上限
String的数据结构是简单的key-value模型,value可以是字符串也可以是数字
常用命令
set
mset
setex(设置过期时间)
setnx(常用于分布式锁)
get
mget
incr(常用于设置浏览量,阅读量)
incrby 可以指定参数一次增加的数值
decr
decrby
append
strlen
getrange s 0 5 得到某个索引区间的
setrange s 0 ss 从某个点开始替换
del
设置对象
set user:1 {name:zhangsan,age:3}
设置一个user:1对象,值为json字符串来保存一个对象。
这是一个巧妙的设计:user:{id}:{field} 如此设置在Redis中是完全OK的。
getset命令:先get然后再set
如果设置的键不存在值,则设置值,并且返回nil
如果设置的键存在值,则返回该值,并设置新的值
hash
键值对的集合
常用来表示对象
hset key field value
hmset
hget
hmget
hexists判断哈希表中的字段是否存在
hdel
hgetall
hvals
hkeys
hlen
hincrby
hsetnx
list链表
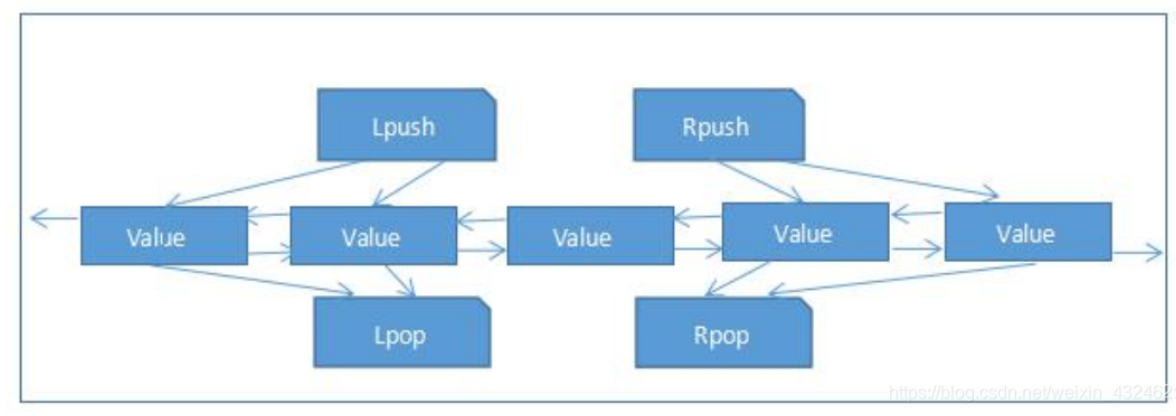
Redis 的链表是简单的字符串列表,排序插入顺序。您可以添加元素到 Redis 的列表的头部或尾部
Lpush:表示的是向链表的左添加,也就是向链表的头添加;
Rpush:表示的是向链表的右添加,也就是向链表的尾添加;
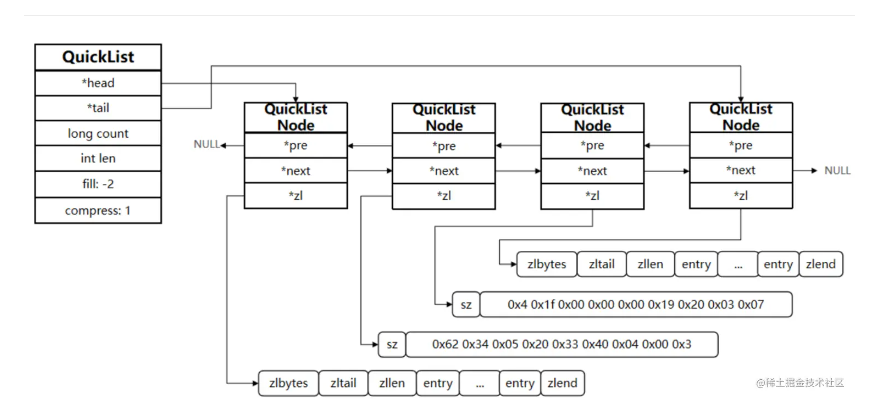
在 3.2 版本之前,Redis 采用 ZipList 和 LinkedList 来实现 List,当元素数量小于 512 并且元素大小小于 64 字节时采用 ZipList 编码,超过则采用 LinkedList 编码。在 3.2 版本之后,Redis统一采用 QuickList 来实现 List。
压缩列表新增某个元素或修改某个元素时,如果空间不不够,压缩列表占用的内存空间就需要重新分配。而当新插入的元素较大时,可能会导致后续元素的 prevlen 占用空间都发生变化,从而引起「连锁更新」问题,导致每个元素的空间都要重新分配,造成访问压缩列表性能的下降
空间扩展操作也就是重新分配内存,因此连锁更新一旦发生,就会导致压缩列表占用的内存空间要多次重新分配,这就会直接影响到压缩列表的访问性能。
所以说,虽然压缩列表紧凑型的内存布局能节省内存开销,但是如果保存的元素数量增加了,或是元素变大了,会导致内存重新分配,最糟糕的是会有「连锁更新」的问题。
因此,压缩列表只会用于保存的节点数量不多的场景,只要节点数量足够小,即使发生连锁更新,也是能接受的。
Quicklist 解决办法,通过控制每个链表节点中的压缩列表的大小或者元素个数,来规避连锁更新的问题。因为压缩列表元素越少或越小,连锁更新带来的影响就越小,对其进行遍历操作所需要的时间代价也变得可以接受,从而提供了更好的访问性能。
所以,QuickList 要做的事情就是
- 限制 ZipList 的长度和 entry 大小
- 通过链表的结构来管理每一个 ZipList 节点
常用于消息队列,消息排队,队列系统
set
集合是字符串的无需集合,不允许有重复的,通过hash table实现
sadd key value
scard key
smembers key
sismember key value
srem key value
srandmember key nums
spop key
smove source destination member ..
应用场景 微博,用户将所有关注的人放入到一个set集合之中,将他的粉丝也放到一个集合中
共同关注,共同爱好,二度好友,好友推荐
zset(SortedSet)
跳表+哈希表
应用场景:班级成绩单,工资表
三种特殊类型
Geospatial地理位置 底层是zset
Hyperloglog基数统计
Bitmap位图场景
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。