innodb
默认级别可重复读,但在很大程度上避免了幻读现象,解决的方案由两种:
- 针对快照读(普通select语句),通过MVCC的方式解决幻读,在可重复读隔离级别下,事务执行过程中看到的数据,一直跟这个事务启动时看到的数据是一致的,即使中途有其他事务插入了一条数据,是查询不出这条数据的,所以很好的避免了幻读现象
- 针对当前读(select…for update等语句),通过next-key lock(记录锁+间隙锁)方式解决了幻读,当执行select…for update语句的时候,会加上next-key lock,如果有其他事务在next-key lock锁范围内插入了一条记录,那么这个插入语句就会被阻塞,无法成功插入,所以就很好避免了幻读问题。
innodb存储数据
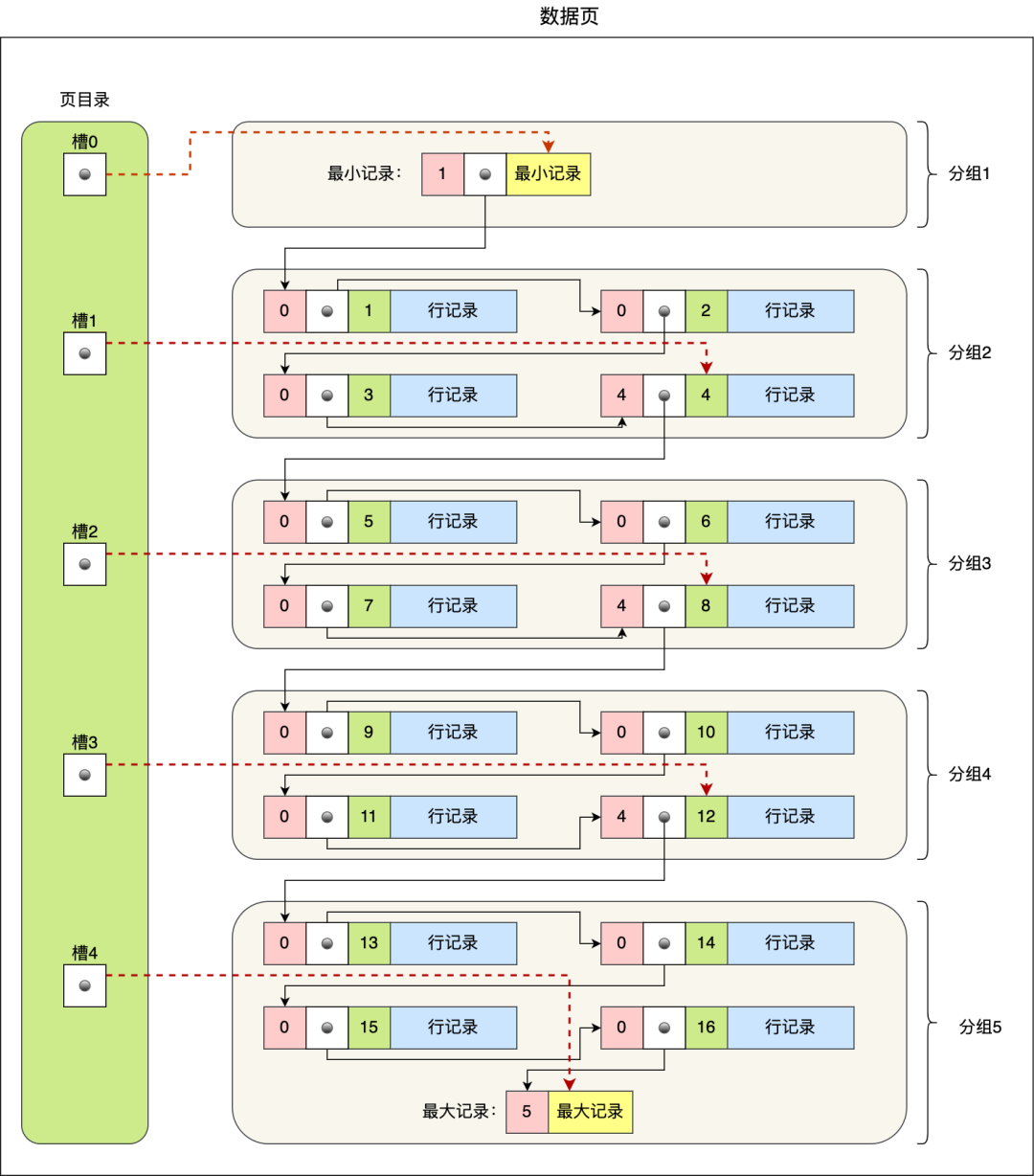
记录是按行进行存储的,但是数据库不能按照一行一行读取,因为太慢。所以innodb的数据按照数据页进行读取,也就是说我以页为单位将整体读入内存(数据页默认大小16kb)。
每个数据页中的记录会以主键顺序组成单向链表,同时按照分组设置页面槽,进行快速搜索,类似目录
innodb使用b+树
当存储查询大量页面,需要多个数据页,而采用b+树解决了如果快速定位记录的问题
在b+树中每个节点都是一个数据页
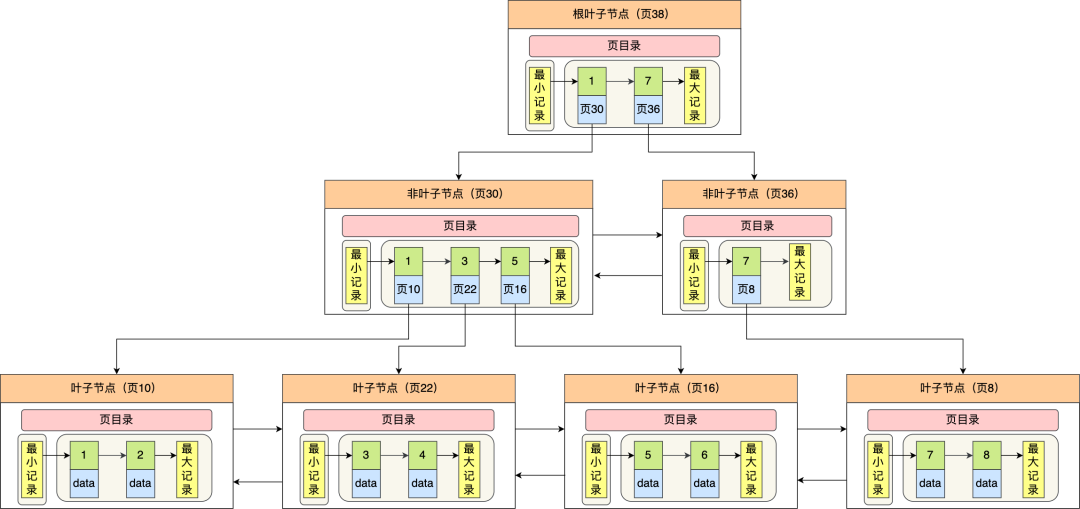
使用b+树的优点:
- b+树的非叶子节点不存放实际的记录数据,仅存放索引,因此数据量相同的情况下,相比b树,b+树的非叶子节点可以存放更多的索引,因此b+树会更矮胖一些,查询的i/o次数会更少
- b+树有大量的冗余节点,使得b+树在插入和删除的时候效率更高,比如删除根节点的时候,不会像b树那样发生复杂的树的变化。
- b+树叶子节点之间用链表连接,利于范围查询,而b树要实现范围查询,需要遍历树,i/o操作次数多,效率不高。
innodb对mvcc的实现
mvcc
多版本并发控制,用于在多个并发事务同时读写数据库时保持数据的一致性和隔离性。主要通过在每个数据行上维护多个版本的数据来实现的。当某个事务要对数据库中的数据进行修改时,mvcc会为该事务创建一个数据快照,而不是直接修改实际的数据行。
通俗来说分读操作和写操作,读操作会使用旧版本的快照,写操作会创建新版本。
对于版本的回收,防止数据库中版本无限增长,mvcc会定期回收
一致性非锁定读
一致性非锁定读通常做法是加一个版本号或者时间戳字段,在更新数据的同时版本号+1或者更新时间戳。查询时,将当前可见的版本号与对应记录的版本号进行比对,如果记录的版本小于可见版本,则改记录可见。
在innodb中,多版本孔子就是对非锁定读的实现,如果读取的行正在执行delete和update操作,这时读操作不会去等待行上锁的释放。而是会去读取行的一个快照数据,对于这种读取历史数据的方式,我们叫他快照读。
**innodb在实现repeatable read时,如果执行的是当前读,则会对读取的记录使用next-key lock,来防止其他事务在间隙间插入数据。
innodb对mvcc的实现
隐藏字段,read view,undo log
不同事务下mvcc的差异
rc事务下会在每次查询时生成一个read view列表(m_ids列表),也就是说会更新不应该看到的事务列表
rr事务下只会在事务开始后第一次查询生成一个read view列表。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。