mysql基本操作-dql
dpl:data query language,用来查询数据库中表的记录。
语法:
select
字段列表
from
表名列表
where
条件列表
group by
分组字段列表
having
分组后条件列表
order by
排序字段列表
limit
分页参数
基本查询
select 字段列表 from 表名; select * from 表名; select 字段1[as 别名]... from 表名; select distinct 字段列表 from 表名;#去除重复操作条件查询(where)
聚合函数(count,max,min,avg,sum)
将一列数据作为一个整体,进行纵向计算(null值不参与聚合函数的运算)
select 聚合函数(字段列表) from 表名;分组查询(group by)
select 字段列表 from 表名 [where 条件] group by 分组字段名 [having 分组后过滤条件];where和having区别
执行时机不同:where是分组之前进行过滤,不满足where条件,不参与分组;而having是分组之后对结果进行过滤。
判断条件不同:where不能对聚合函数进行判断,而having可以。
排序查询(order by)
select 字段列表 from 表名 order by 字段1 排序方式,字段2 排序方式;# asc 升序,desc 降序分页查询(limit)
select 字段列表 from 表名 limit 起始索引,查询记录数;
dql执行顺序
from->where->group by->having->select->order by->limit
当执行一条select语句,期间发生什么?
比如:
select * from p where id = 1;
mysql执行流程
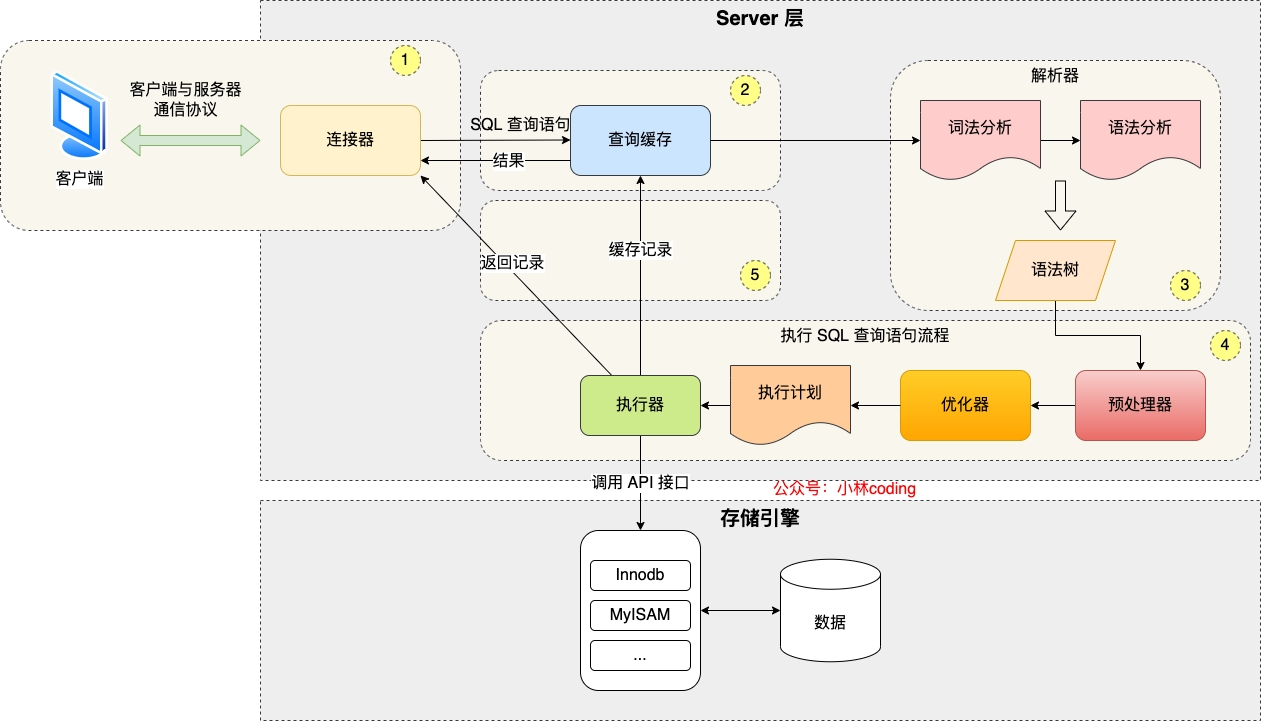
- server层负责建立链接,分析和执行sql
客户端和mysql服务器建立连接的过程也是tcp,可以执行短链接和长连接,长连接的好处是减少建立连接和断开连接的过程,一般推荐使用长连接,因为大部分情况下执行多条sql;但是长连接会提高内存的占用
解决长连接内存占用的方法:
- 定期断开长连接
- 客户端主动重置连接,mysql5.7版本实现了mysql_reset_connection()接口函数,当一个客户端执行一个很大的操作后,在代码里调用mysql_reset_connection函数来重置连接,达到释放内存的效果。这个过程不需要重连和重新做权限验证,但是会将连接恢复到刚刚创建完的状态。
- 存储引擎层负责数据的存储和提取
第一步连接器
tcp三次连接,验证账户密码
当一个用户已经建立了连接,即使管理员中途修改了该用户的权限,也不会影响已经存在连接的权限,只有当新建新的连接才会使用新的权限校验
第二步查询缓存
发送sql语句,根据sql语句的第一个字段解析,查看是什么类型的语句
当是select时会查询缓存数据,看之前是否查询过,key-value的形式存放,key是sql语句,value是结果
查询命中直接返回,没有命中继续执行,执行完然后存入查询缓存中。
mysql8.0开始取消了查询缓存
解析sql
通过解析器:
- 词法分析:识别关键字和非关键字
- 语法分析:判断是否符合mysql语法,没问题构建sql语法树
其中判断表不存在和字段不存在并不是解析器做的,解析器只负责检测语法和构建语法树
执行sql
每条select语句主要分为三个阶段
- prepare阶段:预处理阶段 通常判断表是否存在,mysql5.7是在解析器之后,prepare之前检查的,mysql8是直接在解析器中做的
- optimize阶段:优化阶段 确定执行方案 比如确定使用哪个索引
- execute阶段:执行阶段 执行器和存储引擎交互,交互是以记录为单位的。
索引下推:
主要针对联合索引进行优化,当不采用索引下推,每一次存储引擎找到记录都需要回表,然后将完整的记录传给server层,然后server层单独判断之后的条件;当使用索引下推,可以直接在存储引擎中过滤记录,然后执行回表操作
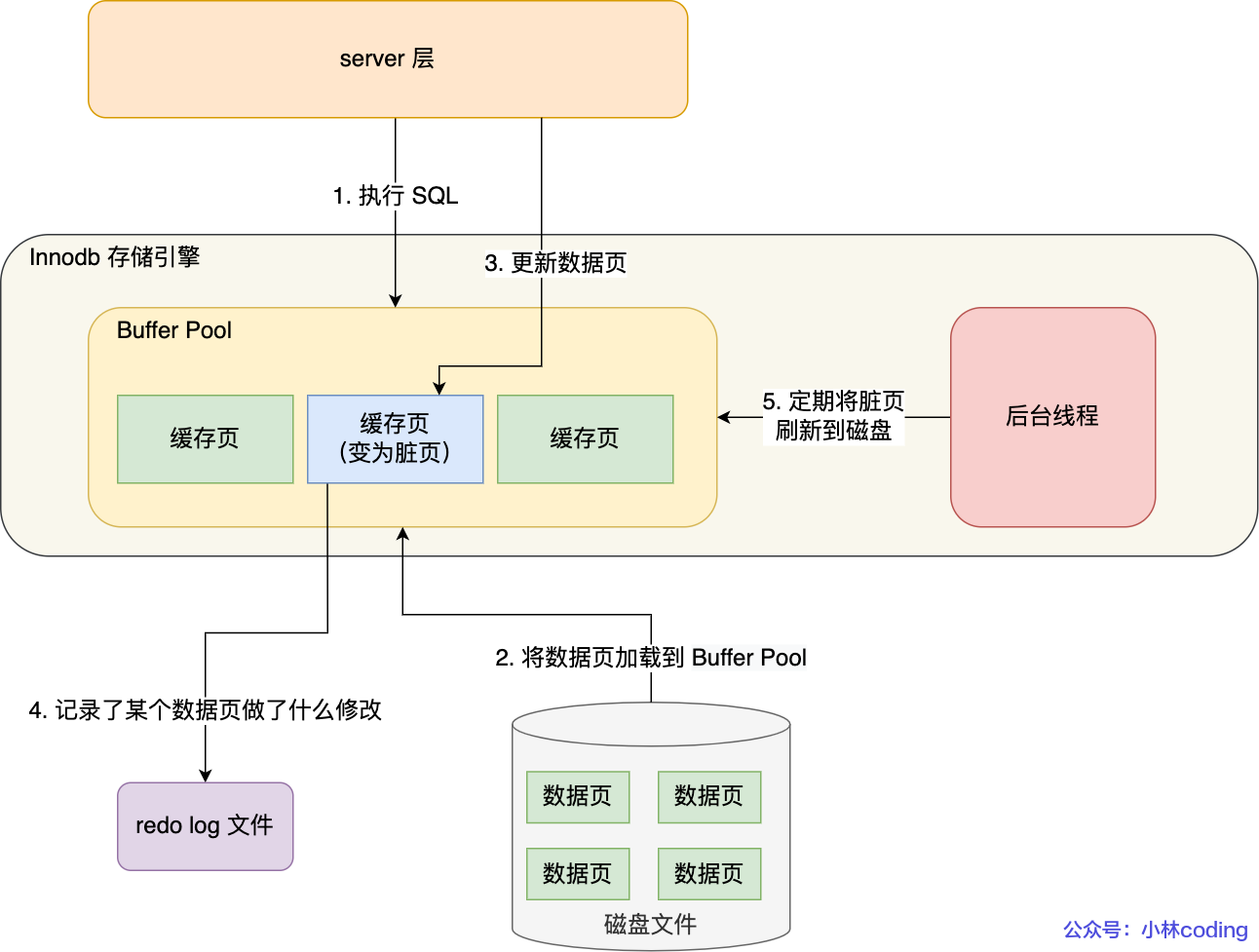
日志
undo log(回滚日志):存储引擎层生成的日志,实现了事务中的原子性,用于事务回滚和mvcc(通过ReadView+undo log实现mvcc)
redo log(重做日志):存储引擎层生成的日志,实现了事务中的持久性,用于掉电等故障
binlog(二进制日志):server层生成的日志,用于数据备份和主从复制
redo log和undo log的区别:
undo log记录了本次事务开始前的数据状态,记录的是更新前的值
redo log记录了本次事务完成后的数据状态,记录的是更新后的值
WAL技术
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。